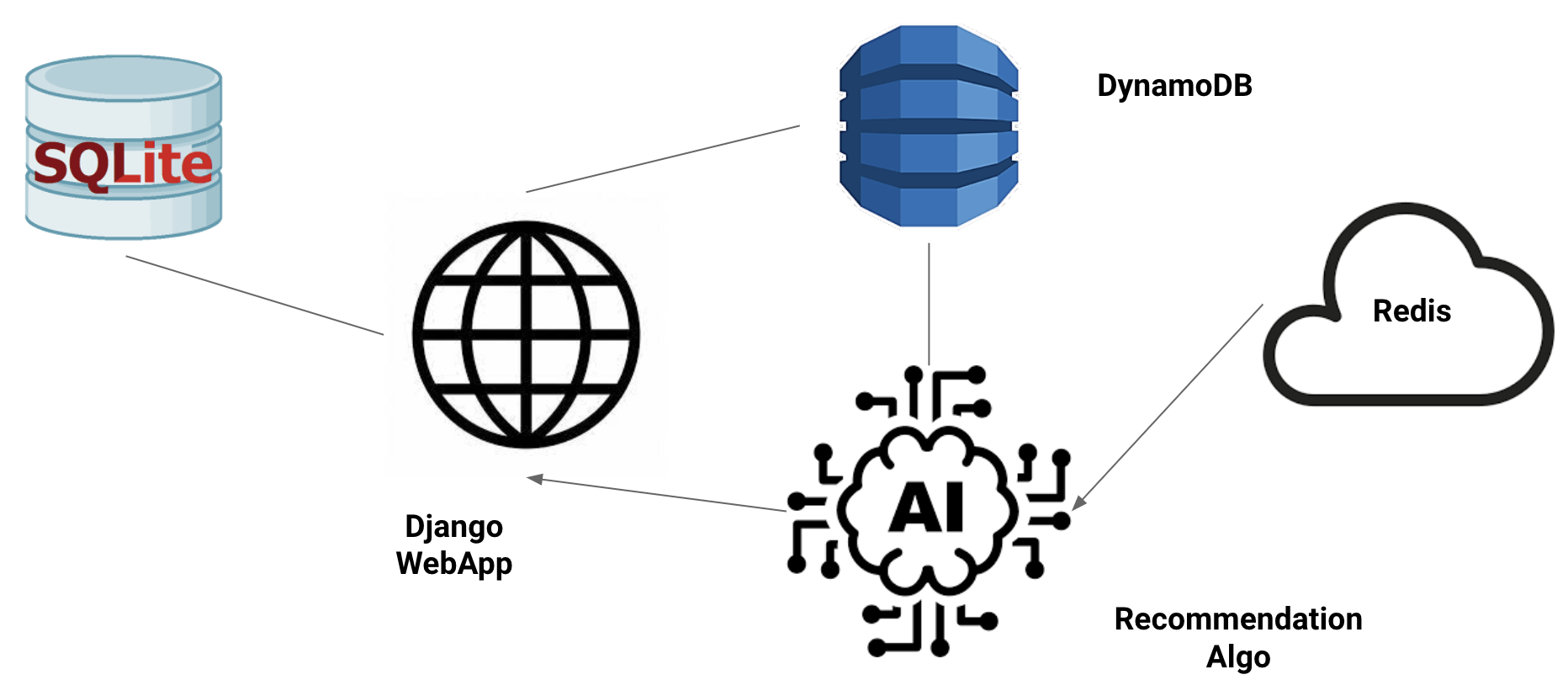
Project Architecture
We have used Django framework to build the OnlyMemes website. The important components interacting with app include DynamoDB, SQLitedb and Redis cache. Our Recommendation algorithm is integrated with Django app and runs as a server side function.
- The Django app is the platform through which users would view the memes. It is responsible for user registration and authenication. It also renders the users feed and communicates with the DynamoDB to update and retrieve the user data. when the feed of the user is rendered, there is an AJAX callback from the client to the server which triggers the recommendation algorithm to produce the next feed for the user.
- SQLitedb is used for user registraion and authenication. This database would be accessed only at the login and registration pages
- DynamoDB contains the data and tables necessary for running the webapp and the recommendation algorithm
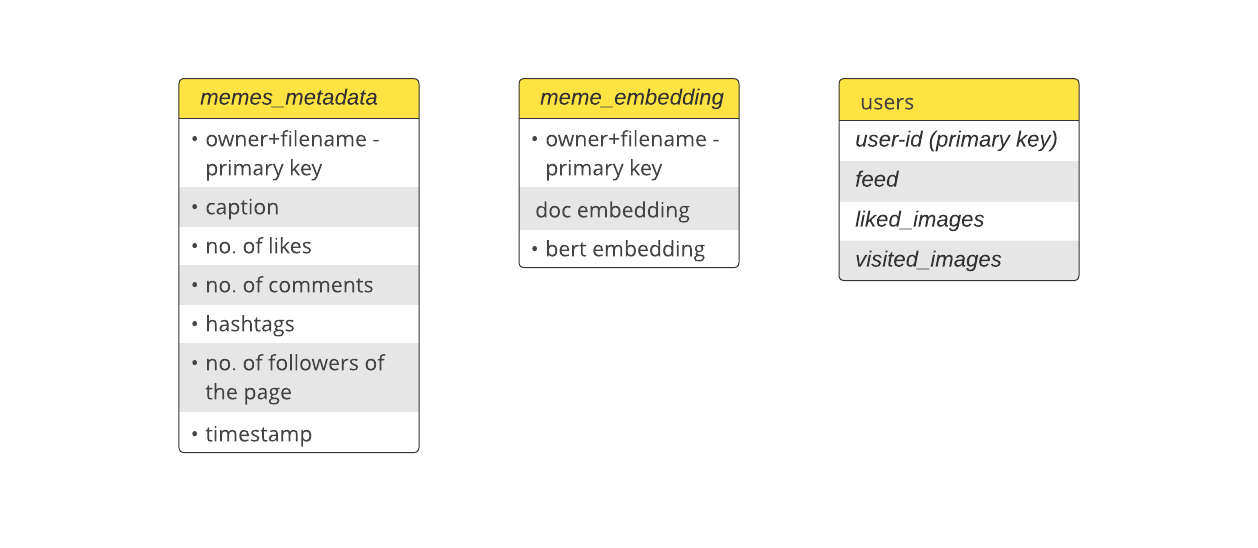
we have three important tables for our application.
1) memes_metadata
The memes metadata table contains the information related to the data extracted from instagram. This table would be used by the recommendation algorithm for computing similarity scores and final rank
2) meme_embeddings
Our recommendation alogrithm runs based on the similarity of the hashtags. The hastags of the memes are fixed
So, we are precomputing the bert and doc embedding and storing in the DynamoDB. The recommendation algorithm would pull these embeddings from the DynamoDB for ranking the memes.
3) users
The users table is used both by the webapp and the recommendation algorithm
- Redis is used as cache to store the word2vec embeddings of the hashtags present in the memes_metadata. This component is needed as the word2vec model (google-news-300) is a 1.5GB binary file and takes more than 90s to load the model. By using Redis, the total runtime of the recommendation algorithm got reduced to 18s making the recommendation faster by 5X.
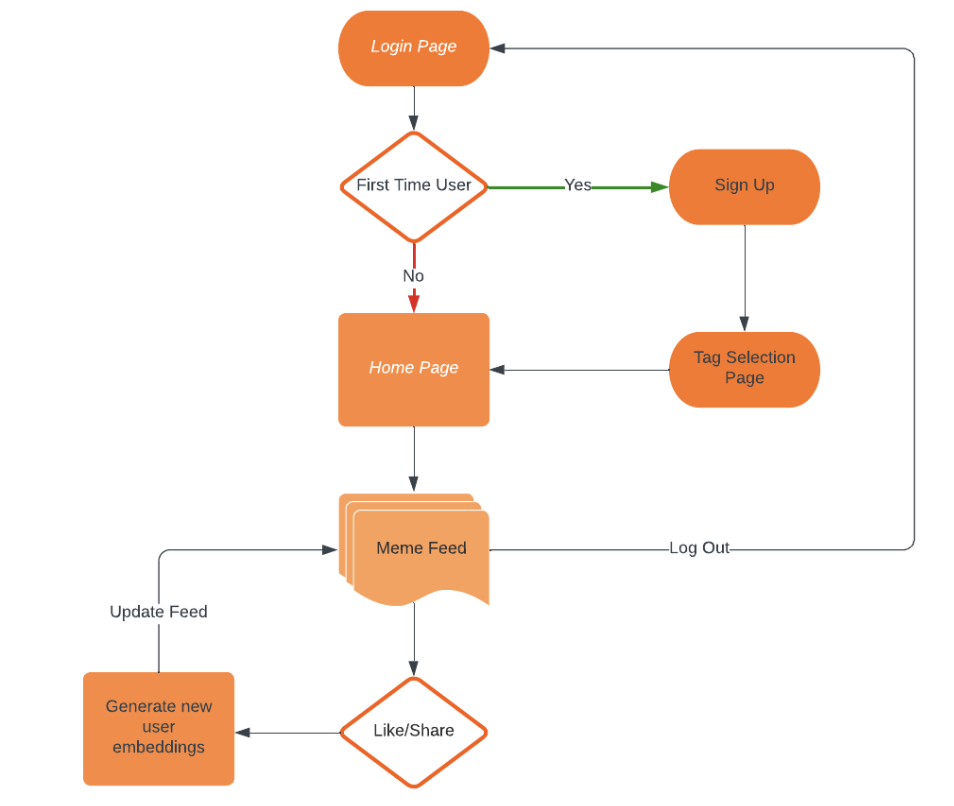
Django Workflow
We have developed a web application for our recommender system using the Django Framework with Python, and DynamoDB for the database. The landing page of our web application prompts users to log in and offers a sign-up function for new users.
- Data from user sign-up is kept in SQLitedb for authentication activities
- To address the cold start problem, we provide users with a selection of curated meme tags upon sign-up.
- Our recommendation algorithm runs in the backend and curates the content on the homepage based on the selected tags. This approach helps users receive personalized recommendations, even if they have no previous search history.
- User embeddings are updated based on the implicit user input such as likes and clicks. Using the updated embeddings our web application pulls new feed data from DynamoDB.
The web application is designed and developed in line with user's preferences which is updated periodically using user interactions. It is designed to incorporate minimum user intervention while ensuring maximum user satisfaction.
Recommendation Engine
Generating Meme/User Embedding
To recommend memes to users based on their interest and interaction with the feed, we use a content-based recommendation system. We tried extracting the meme text from using OCR but with our dataset consisting of a mix of images and videos, the quality of extracted meme text data was not sufficient to train our recommendation model. Thus we used the hashtags of the memes for generation embeddings for all the memes. To generate embeddings we used two methods as given below:
- Word2vec: Word2vec is a popular natural language processing technique used for generating word embeddings, which are numerical representations of words in a high-dimensional space. The goal of word2vec is to capture the semantic meaning of words by training a neural network on a large corpus of text. In this project, we used Google News 300 Word2vec pre-trained model to create a word2vec higher dimensional representation. By using word2vec to generate embeddings for hashtags associated with memes, we can capture the semantic meaning of the hashtags and use them to create more accurate and effective representations of the memes.
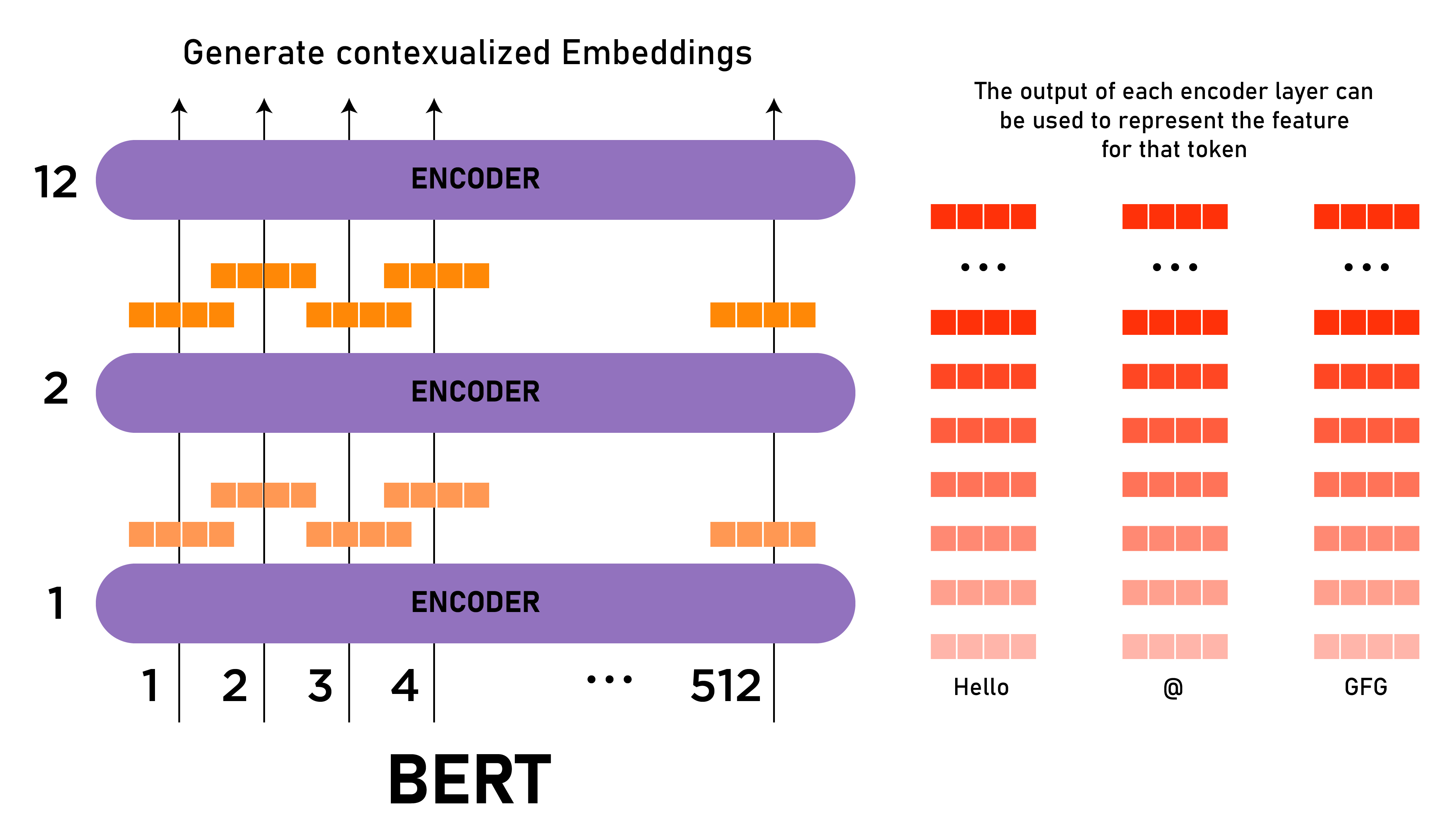
- BERT Bidirectional Encoder Representations from Transformers is a deep learning model that uses a combination of unsupervised and supervised learning to generate contextualized word embeddings. It uses a transformer architecture, which is a type of neural network that can process entire sequences of data at once, to encode the context of each word in a sentence. We used pre-trained BERT on meme tags and user queries to generate BERT-based dense embeddings. BERT is capable of capturing the relationships between words in a given sentence, which can be useful for generating embeddings that represent the overall meaning of a meme based on its associated hashtags and also can handle out-of-vocabulary words, which can be common in memes that often use non-standard or invented words or phrases.
Soft Cosine Similarity
Soft cosine similarity is a measure of similarity between two text documents or vectors that take into account the semantic similarity between their constituent words or features. Unlike traditional cosine similarity, which only measures the cosine of the angle between two vectors in a high-dimensional space, soft cosine similarity also considers the relationships between the words or features in the two vectors. Given below are the advantages of using soft cosine similarity:- Takes into account the semantic similarity between the dimensions of the vectors
- Can compare vectors of different types
Generating User Queries
To tackle the cold start problem we give users a set of tags or interests to choose from. From these tags, the user selects his/her favorite tags, and based on those we generate the initial embeddings for the user. We then show the user the feed based on the initial user embedding. When the user interacts with the memes by liking or sharing we change the user query by adding the tags of these memes to the original chosen tags. Based on the updated user query we generate new embeddings for the user and get an updated feed of memes ranked based on the criteria given below.
Generating Feed and Ranking Memes
We generate the updated feed based on the user interaction dynamically. We have a list of memes that the user has already seen and also a list of liked memes. Based on the current user embedding we calculate the similarity with all memes embeddings. Finally, we calculate the score for each meme based on two factors:- Similarity
- Popularity (Number of Likes and comments)
Demo Flow Screenshots
Youtube Video Link
The application asks the user to login at the start. If the user is new, we ask the user to select favourite hashtags and this solves the cold start problem. In the demo we had selected 4 tags: 'dog', 'anime', 'friends', 'school'. Based on these tags we get the first feed after which we like memes related to cats. Thus we can see that in the next feed we are shown more cat memes. This signifies that our recommender is working dynamically to suggest relevant memes.
| Our method | Baseline | |
|---|---|---|
| Average precision@20 | 0.85 | 0.72 |
| Average NDCG | 0.74 | 0.68 |
Evaluation
Evaluation is a crucial part of the recommendation system and is required for testing the performance of methods used for recommendation. In our case, we use a content-based recommendation system for memes and rank the memes based on the similarity between embeddings. While there are other factors like popularity and diversification of feed using random popular memes, we only evaluate the similarity part of our system with the baseline method as the other parts are independent of the system used and are just to improve upon the recommendations of our main system.
We compare our method of using Word2vec (trained on Google News 300) and BERT with soft cosine similarity with a baseline method we implemented in class using Wor2Vec embeddings with cosine similarity. We manually define images that are relevant for each tag and then compare these methods on two metrics Precision@20 and NDCG by using these methods to get the top 20 memes for these hashtags.
- Precision@20 - It measures the proportion of recommended items that are relevant to the user, out of the top 20 recommended items.
precision@20 = (# of relevant items in top 20 recommended items) / 20
- NDCG NDCG (Normalized Discounted Cumulative Gain) measures the relevance and position of each recommended item and assigns a score to the list of recommended items based on these factors.
NDCG = DCG / IDCG
Conclusion
Challenges
As we built OnlyMemes there were a few challenges that we tackled during this project.
- Data Gathering - We build a script to scrape memes from Instagram as a dataset for this project but due to API rate limitation this was a major roadblock in the data gathering process. To tackle this we used some tweaks to gather data by designing a continuous scraping process with rate limitation
- Meme content extraction - As the data extracted was a mix of videos and images and the content of images was also not uniform it was a challenge to extract meme text using OCR. We tried all models like Tesseract, EasyOCR, and KerasOCR but the quality of the meme text data extracted was not good or missing for most of the posts. Thus we decide to run our models only on meme tags.
- Cold Start - To eliminate the cold start problem we implemented the Spotify/Netflix approach to let users choose a set of favorite tags initially. Also as new memes are added daily this is not a concern in our system as we can create image embedding using tags
- Design Decisions - There were many design decisions for the application like when to update the feed, how to update the feed. We used the principles taught in class like minimizing user traction for using the app and diversification of feed to take these design decisions
Way Forward
As the timeline of this project was limited, we can think of a few improvements that we can add to our application.
- More Data We look forward to using a larger dataset with more quality memes to improve our recommendations
- Meme Text Extraction With large and good-quality data we can implement OCR for meme text extraction and use meme text and tags to build meme embeddings
- Meme Tag Generation Sometimes memes are not tagged or captioned properly thus we can extract meme text, and meme content to generate meme tags to include such memes in our system. This would be possible using deep learning models to be trained on meme content to predict the tags.